Scrapy介绍
Scrapy是一个用于网络爬虫的开源框架,由 Python 编写。
Scrapy 是一个强大且易于使用的爬虫工具,可以帮助开发者从网站上抓取和提取数据。它具有许多优点,如高度可定制、易于学习、稳定且高效。
Scrapy 的核心功能如下:
1. 简单易用的 API:Scrapy 提供了一套简洁的 API,使得开发者可以轻松地编写爬虫程序。
2. 强大的爬虫引擎:Scrapy 具有强大的爬虫引擎,可以自动跟踪网页的 HTML 标签和属性,适应不同的网站结构。
3. 选择性爬取:Scrapy 支持根据需求爬取特定内容,例如:提取文章标题、摘要、图片等。
4. 异步请求:Scrapy 可以进行异步请求,避免拥堵目标服务器,提高爬取效率。
5. 设置延迟:可以设置爬取任务的执行时间,避免对目标服务器造成过大压力。
6. 设定爬取上限:可以设置每个域名或 URL 的最大请求数,以遵守网站的爬虫政策。
7. 代理支持:支持使用代理 IP 进行爬取,提高隐蔽性和安全性。
8. 分布式调度:Scrapy 支持分布式调度,可以将爬取任务分发到多台服务器上,提高爬取速度。
9. 天然反反爬虫:Scrapy 遵循 200 行规则,在一定程度上可以绕过反爬虫机制。
10. 存储和解析数据:Scrapy 可以将爬取到的数据存储到本地,并支持多种数据格式,如 CSV、JSON、XML 等。此外,Scrapy 还提供了数据解析功能,方便开发者提取所需信息。
11. 扩展性强:Scrapy 有丰富的扩展库和中间件,可以根据实际需求进行定制。
总之,Scrapy 是一个功能丰富、易于使用的网络爬虫框架,广泛应用于数据挖掘、网络监测、竞争分析等领域。

在本文中,我们将为大家构建一个抓取工具,希望用 Python 程序从 目标网站 抓取数据以抓取新问题(问题标题和 URL)。然后,抓取的数据应存储在MongoDB中。值得注意的是,Stack Overflow 有一个 API,可用于访问完全相同的数据。
但是,今天我们要自己实现一个 抓取工具,所以 开始吧:
第一:抓取对象网站的情况
在开始任何抓取工作之前,请务必查看网站的使用/服务条款并尊重 robot.txt文件。确保遵守合乎道德的抓取做法,不要在短时间内用大量请求淹没网站。将您抓取的任何网站视为您自己的网站。不能通过高频抓取,把人家网站给抓奔溃了。
第二:安装环境
我们需要 Scrapy 库 (v1.0.3) 和 PyMongo (v3.0.3) 来将数据存储在 MongoDB 中。您还需要安装 MongoDB
如果您运行的是 OSX 或 Linux 版本,请使用 pip 安装 Scrapy:
shell
$ pip install Scrapy==1.0.3
$ pip freeze > requirements.txt如果您使用的是 Windows 计算机,则需要手动安装多个依赖项。有关详细说明,请参阅官方文档以及我创建的这个 Youtube 视频。
设置 Scrapy 后,通过在 Python 代码中运行以下命令来验证您的安装
python
>>> import scrapy
>>>如果你没有收到错误,那么你就可以开始了!
安装 PyMongo with pip:
$ pip install pymongo
$ pip freeze > requirements.txt现在就可以构建项目
scrapy 可以提供命令去构建一个项目新建 Scrapy project:
$ scrapy startproject stack2015-09-05 20:56:40 [scrapy] INFO: Scrapy 1.0.3 started (bot: scrapybot)
2015-09-05 20:56:40 [scrapy] INFO: Optional features available: ssl, http11
2015-09-05 20:56:40 [scrapy] INFO: Overridden settings: {}
New Scrapy project 'stack' created in:
/stack-spider/stack
You can start your first spider with:
cd stack
scrapy genspider example example.com
创建了一个目录:├── scrapy.cfg
└── stack
├── __init__.py
├── items.py
├── pipelines.py
├── settings.py
└── spiders
└── __init__.py
items.py 文件用于为我们计划抓取的数据定义存储“容器”。
该类继承自 (docs),它基本上有许多 Scrapy 已经为我们构建的预定义对象:StackItem()Item
python
import scrapy
class StackItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
pass让我们添加一些我们真正想要收集的物品。对于每个问题,客户都需要标题和 URL。因此,请像这样更新 items.py:
from scrapy.item import Item, Field
class StackItem(Item):
title = Field()
url = Field()现在就可以构建爬虫
在“spiders”目录中创建一个名为 stack_spider.py 的文件。
首先定义一个继承自 Scrapy 的类,然后根据需要添加属性:Spider
from scrapy import Spider
class StackSpider(Spider):
name = "stack"
allowed_domains = ["stackoverflow.com"]
start_urls = [
"http://stackoverflow.com/questions?pagesize=50&sort=newest",
]前几个变量是不言自明的(文档):
name定义 Spider 的名称。allowed_domains包含允许爬虫爬网的域的 base-URL。start_urls是爬虫要从中开始抓取的 URL 列表。所有后续 URL 都将从爬虫从 中的 URL 下载的数据开始。start_urls
XPath 选择器
接下来,Scrapy 使用 XPath 选择器从网站中提取数据。换句话说,我们可以根据给定的 XPath 选择 HTML 数据的某些部分。正如 Scrapy 的文档中所述,“XPath 是一种用于在 XML 文档中选择节点的语言,它也可以与 HTML 一起使用。
您可以使用 Chrome 的开发者工具轻松找到特定的 Xpath。只需检查特定的 HTML 元素,复制 XPath,然后根据需要进行调整:
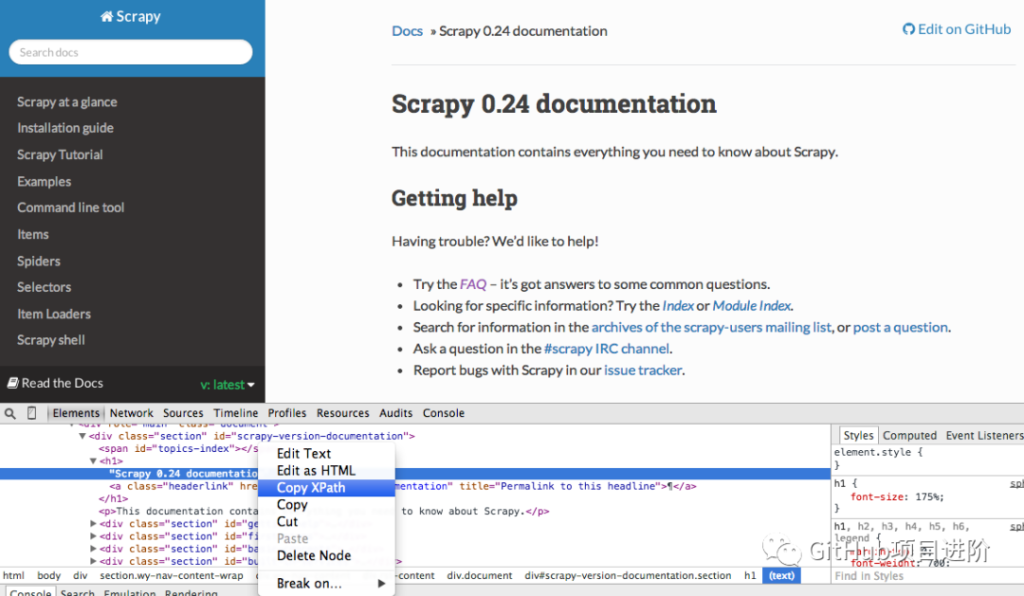
开发人员工具还使您能够在 JavaScript 控制台中使用以下方法测试 XPath 选择器:$x$x("//img")

同样,我们基本上告诉 Scrapy 从哪里开始根据定义的 XPath 查找信息。让我们导航到 Chrome 中的 Stack Overflow 站点并找到 XPath 选择器。
右键单击第一个问题,然后选择“检查元素”:
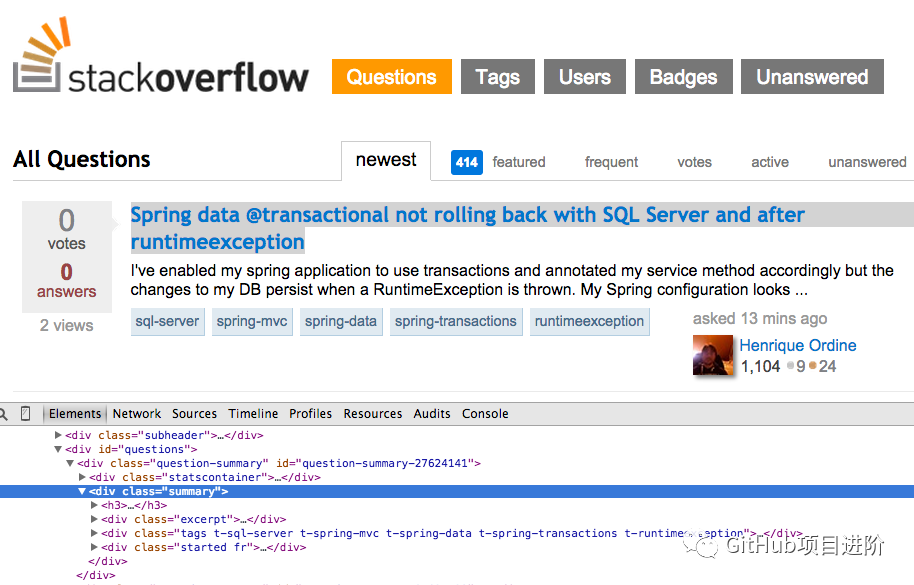
现在获取 、 的 XPath,然后在 JavaScript 控制台中对其进行测试:<div class="summary">//*[@id="question-summary-27624141"]/div[2]

正如你所知道的,它只是选择了一个问题。因此,我们需要更改 XPath 来获取所有问题。有什么想法吗?这很简单:.这是什么意思?从本质上讲,此 XPath 声明:获取所有 <h3> 元素,这些元素是具有 summary 类的 <div> 的子元素。在 JavaScript 控制台中测试此 XPath。//div[@class="summary"]/h3
请注意,我们没有使用 Chrome 开发者工具的实际 XPath 输出。在大多数情况下,输出只是一个有用的旁白,它通常为您指明查找工作 XPath 的正确方向。
现在让我们更新stack_spider.py脚本:
stack_spider.py script:
from scrapy import Spider
from scrapy.selector import Selector
class StackSpider(Spider):
name = "stack"
allowed_domains = ["stackoverflow.com"]
start_urls = [
"http://stackoverflow.com/questions?pagesize=50&sort=newest",
]
def parse(self, response):
questions = Selector(response).xpath('//div[@class="summary"]/h3')提取数据
我们仍然需要解析和抓取我们想要的数据,像这样更新stack_spider.py:
<div class="summary"><h3>
like so:from scrapy import Spider
from scrapy.selector import Selector
from stack.items import StackItem
class StackSpider(Spider):
name = "stack"
allowed_domains = ["stackoverflow.com"]
start_urls = [
"http://stackoverflow.com/questions?pagesize=50&sort=newest",
]
def parse(self, response):
questions = Selector(response).xpath('//div[@class="summary"]/h3')
for question in questions:
item = StackItem()
item['title'] = question.xpath(
'a[@class="question-hyperlink"]/text()').extract()[0]
item['url'] = question.xpath(
'a[@class="question-hyperlink"]/@href').extract()[0]
yield item
````
We are iterating through the `questions` and assigning the `title` and `url` values from the scraped data. Be sure to test out the XPath selectors in the JavaScript Console within Chrome Developer Tools - e.g., `$x('//div[@class="summary"]/h3/a[@class="question-hyperlink"]/text()')` and `$x('//div[@class="summary"]/h3/a[@class="question-hyperlink"]/@href')`.
## Test
跑一下试试
```console
$ scrapy crawl stack除了 Scrapy 堆栈跟踪外,您还应该看到输出的 50 个问题标题和 URL。您可以使用以下小命令将输出呈现到 JSON 文件:
command:
$ scrapy crawl stack -o items.json -t json我们现在已经根据我们正在寻找的数据实现了我们的 Spider。现在我们需要将抓取的数据存储在MongoDB中。
将数据存储在 MongoDB 中
每次返回项目时,我们都希望验证数据,然后将其添加到 Mongo 集合中。
第一步是创建我们计划用于保存所有已爬网数据的数据库。打开 settings.py 并指定管道并添加数据库设置:
database settings:
ITEM_PIPELINES = ['stack.pipelines.MongoDBPipeline', ]
MONGODB_SERVER = "localhost"
MONGODB_PORT = 27017
MONGODB_DB = "stackoverflow"
MONGODB_COLLECTION = "questions"管道管理
我们已经设置了爬虫来抓取和解析 HTML,并且我们已经设置了数据库设置。现在,我们必须通过 pipelines.py 中的管道将两者连接在一起。
连接到数据库
首先,让我们定义一个实际连接到数据库的方法:
connect to the database:
import pymongo
from scrapy.conf import settings
class MongoDBPipeline(object):
def __init__(self):
connection = pymongo.MongoClient(
settings['MONGODB_SERVER'],
settings['MONGODB_PORT']
)
db = connection[settings['MONGODB_DB']]
self.collection = db[settings['MONGODB_COLLECTION']]在这里,我们创建一个类,我们有一个构造函数,通过定义 Mongo 设置然后连接到数据库来初始化类。MongoDBPipeline()
处理数据
接下来,我们需要定义一个方法来处理解析后的数据:
process the parsed data:
import pymongo
from scrapy.conf import settings
from scrapy.exceptions import DropItem
from scrapy import log
class MongoDBPipeline(object):
def __init__(self):
connection = pymongo.MongoClient(
settings['MONGODB_SERVER'],
settings['MONGODB_PORT']
)
db = connection[settings['MONGODB_DB']]
self.collection = db[settings['MONGODB_COLLECTION']]
def process_item(self, item, spider):
valid = True
for data in item:
if not data:
valid = False
raise DropItem("Missing {0}!".format(data))
if valid:
self.collection.insert(dict(item))
log.msg("Question added to MongoDB database!",
level=log.DEBUG, spider=spider)
return item我们建立与数据库的连接,解压缩数据,然后将其保存到数据库中。现在我们可以再次测试了!
测试
再次,在“stack”目录中运行以下命令:
the “stack” directory:$ scrapy crawl stack
万岁!我们已成功将抓取的数据存储到数据库中:

结论
这是一个非常简单的示例,使用 Scrapy 抓取和抓取网页。实际的自由职业者项目要求脚本遵循分页链接并使用 (docs) 抓取每个页面,这非常容易实现。尝试自己实现它,并在下面发表评论,并附上 Github 存储库的链接,以便快速查看代码。
github地址:
源代码
我们收集了10000+开源项目, 点击 阅读原文