用手机识别扫描文字,目前已经非常成熟,本文介绍
将以上图片文字提取出来

使用 OpenCV 构建文档扫描仪只需三个简单步骤即可完成:
- 步骤1:检测边缘。
- 步骤 2:使用图像中的边缘找到代表正在扫描的纸张的轮廓(轮廓)。
- 步骤 3:应用透视变换以获得文档的自上而下视图。
真的。就是这样。
只需三个步骤,您就可以将自己的文档扫描应用程序提交到 App Store。
听起来很有趣?
请继续阅读。并解锁构建您自己的手机扫描仪应用程序的秘密。
创建一个新文件,将其命名为scan.py,然后让我们开始吧。
#导入必要的包
从 pyimagesearch.transform 导入 four_point_transform
从skimage.filters导入threshold_local
将 numpy 导入为 np
导入argparse
导入CV2
导入imutils
# 构造参数解析器并解析参数
ap = argparse.ArgumentParser()
ap.add_argument(“-i”, “–image”, required = True,
help =“要扫描的图像的路径”)
args = vars(ap.parse_args())
第 2-7 行处理导入我们需要的必要 Python 包。
我们还将使用该imutils 模块,其中包含用于调整图像大小、旋转和裁剪图像的便利功能。imutils 您可以在我的这篇文章中阅读更多相关内容。要安装imutils,只需:$ pip install –upgrade imutils
接下来,让我们threshold_local 从scikit-image导入该函数。此功能将帮助我们获得扫描图像的“黑白”感觉。
第 1 步:边缘检测
使用 OpenCV 构建文档扫描仪应用程序的第一步是执行边缘检测。让我们来看看:# 加载图像并计算旧高度的比例
# 到新的高度,克隆它,并调整它的大小
image = cv2.imread(args[“image”])
ratio = image.shape[0] / 500.0
orig = image.copy()
image = imutils.resize(image, height = 500)
# convert the image to grayscale, blur it, and find edges
# in the image
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
gray = cv2.GaussianBlur(gray, (5, 5), 0)
edged = cv2.Canny(gray, 75, 200)
# show the original image and the edge detected image
print(“STEP 1: Edge Detection”)
cv2.imshow(“Image”, image)
cv2.imshow(“Edged”, edged)
cv2.waitKey(0)
cv2.destroyAllWindows()
首先,我们在第 17 行从磁盘加载图像。
为了加快图像处理速度,并使边缘检测步骤更加准确,我们将扫描图像的大小调整为第17-20 行的 500 像素高度。
我们还特别注意跟踪ratio 图像的原始高度到新高度(第 18 行)——这将使我们能够对原始图像而不是调整大小的图像执行扫描。
从这里开始,我们在第 24行将图像从 RGB 转换为灰度,执行高斯模糊以去除高频噪声(有助于步骤 2 中的轮廓检测),并在第 26 行执行 Canny 边缘检测。
步骤 1 的输出显示在第 30 行和第 31 行。
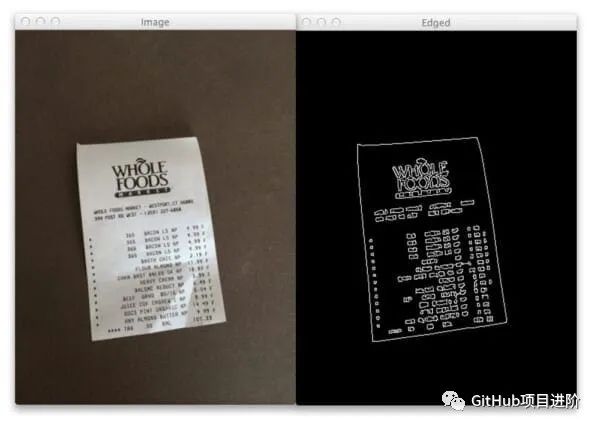
步骤 1 的输出显示在第 30 行和第 31 行。
请看下面的示例文档:
在左边你可以看到我从 Whole Foods 寄来的收据。注意照片是如何以一定角度拍摄的。这绝对不是 90 度、自上而下的页面视图。此外,图中还有我的办公桌。当然,这不是任何手段的“扫描”。我们已经完成了我们的工作。
然而,在右侧您可以看到执行边缘检测后的图像。我们可以清楚地看到收据的轮廓。
不错的开始。
让我们继续步骤 2。
第二步:寻找轮廓
轮廓检测并不一定很困难。
事实上,在构建文档扫描仪时,您实际上拥有一个很大的优势……
花点时间考虑一下我们实际正在构建的内容。
文档扫描仪只需扫描一张纸即可。
假设一张纸是一个矩形。
矩形有四个边。
因此,我们可以创建一个简单的启发式方法来帮助我们构建文档扫描仪。
启发式是这样的:我们假设图像中恰好有四个点的最大轮廓是我们要扫描的纸张。
这也是一个相当安全的假设 – 扫描仪应用程序只是假设您要扫描的文档是我们图像的主要焦点。并且可以安全地假设(或至少应该如此)这张纸有四个边缘。
这正是下面的代码所做的:
# 找到边缘图像中的轮廓,只保留
# 最大的,并初始化屏幕轮廓cnts = cv2.findContours(edged.copy(), cv2.RETR_LIST, cv2.CHAIN_APPROX_SIMPLE)
cnts = imutils.grab_contours(cnts)
cnts = sorted(cnts, key = cv2.contourArea, reverse = True)[:5]
# loop over the contours
for c in cnts:
# approximate the contour
peri = cv2.arcLength(c, True)
approx = cv2.approxPolyDP(c, 0.02 * peri, True)
# if our approximated contour has four points, then we
# can assume that we have found our screen
if len(approx) == 4:
screenCnt = approx
break
# show the contour (outline) of the piece of paper
print(“STEP 2: Find contours of paper”)
cv2.drawContours(image, [screenCnt], -1, (0, 255, 0), 2)
cv2.imshow(“Outline”, image)
cv2.waitKey(0)
cv2.destroyAllWindows()
我们首先在第 37行找到边缘图像中的轮廓。我们还处理了 OpenCV 2.4、OpenCV 3 和 OpenCV 4 在第 38 行以不同方式返回轮廓的事实。
我喜欢做的一个巧妙的性能黑客实际上是按区域对轮廓进行排序,并只保留最大的轮廓(第 39 行)。这使我们能够仅检查最大的轮廓,而丢弃其余的。
然后,我们开始在Line 42上的轮廓上循环,并近似计算Line 44 和 45上的点数。
如果近似轮廓有四个点(第 49 行),我们假设我们已经在图像中找到了文档。
再说一次,这是一个相当安全的假设。扫描仪应用程序将假设 (1) 要扫描的文档是图像的主要焦点,并且 (2) 文档是矩形的,因此将具有四个不同的边缘。
从那里开始,第 55 行和第 56 行显示了我们要扫描的文档的轮廓。
现在让我们看一下示例图像:

正如您所看到的,我们已经成功地利用边缘检测图像来找到文档的轮廓(轮廓),如收据周围的绿色矩形所示。
最后,让我们继续步骤 3,这将是使用我的 four_point_transform 函数的一个简单步骤。
第 3 步:应用透视变换和阈值
构建移动文档扫描仪的最后一步是获取代表文档轮廓的四个点并应用透视变换以获得图像的自上而下的“鸟瞰图”。
让我们来看看:# 应用四点变换以获得自顶向下
# 原始图像的视图warped = four_point_transform(orig, screenCnt.reshape(4, 2) * ratio)
# convert the warped image to grayscale, then threshold it
# to give it that ‘black and white’ paper effect
warped = cv2.cvtColor(warped, cv2.COLOR_BGR2GRAY)
T = threshold_local(warped, 11, offset = 10, method = “gaussian”)
warped = (warped > T).astype(“uint8”) * 255
# show the original and scanned images
print(“STEP 3: Apply perspective transform”)
cv2.imshow(“Original”, imutils.resize(orig, height = 650))
cv2.imshow(“Scanned”, imutils.resize(warped, height = 650))
cv2.waitKey(0)
第 62 行执行扭曲变换。事实上,所有繁重的工作都是由该four_point_transform 函数处理的。同样,您可以在上周的帖子中阅读有关此功能的更多信息。
我们将向 中传递两个参数four_point_transform:第一个是从磁盘加载的原始图像(不是调整大小的图像),第二个参数是表示文档的轮廓乘以调整大小的比率。
那么,您可能想知道,为什么我们要乘以调整大小的比率?
我们乘以调整大小的比率,因为我们执行了边缘检测并在高度 = 500像素的调整大小的图像上找到了轮廓。
然而,我们想要在原始图像上执行扫描,而不是调整大小的图像,因此我们将轮廓点乘以调整大小的比率。
为了获得图像的黑白感觉,我们获取扭曲的图像,将其转换为灰度并在第 66-68 行应用自适应阈值处理。
最后,我们在第 72-74 行显示输出。
Python+OpenCV文档扫描结果
说到输出,请通过运行脚本来查看我们的示例文档:
$ python scan.py –image images/receipt.jpg

左边是从磁盘加载的原始图像。右边是扫描图像!
请注意扫描图像的视角如何变化——我们有一个自上而下的 90 度图像视图。
得益于我们的自适应阈值处理,我们还为文档带来了漂亮、干净的黑白感觉。
我们已经成功构建了文档扫描仪!
所有这些都在不到 5 分钟的时间内完成,代码不到 75 行(无论如何,其中大部分都是注释)。